Everyone’s debating GPT-4 vs. Claude vs. Gemini. Almost nobody’s talking about the infrastructure layer that actually determines whether your agent works in production.
Ask any developer building with OpenClaw what their first decision was, and they’ll tell you which LLM they chose. GPT-4o. Claude Sonnet. Gemini Pro. Maybe a local model running on Ollama.
Ask them about their deployment infrastructure, and you’ll get a shrug. “It’s running on a DigitalOcean droplet.” Or worse: “It’s on my laptop.”
This is the blind spot in the AI agent conversation right now. We’re having an intense, nuanced debate about model selection – benchmarks, context windows, cost per token, reasoning capabilities – while ignoring the fact that deployment infrastructure is what actually determines whether an agent works reliably, safely, and at scale.
I’ve spent months watching OpenClaw deployments succeed and fail across the 230,000+ star ecosystem. The pattern is consistent: the agents that break in production almost never break because of the model. They break because of how they’re deployed.
The Model Debate Is a Distraction (Mostly)
Let me be clear: model choice matters. Different LLMs have different strengths, and selecting the right one for your use case is a legitimate engineering decision.
But here’s the thing. OpenClaw supports 28+ model providers. You can swap models with a configuration change. Moving from GPT-4 to Claude to Gemini is a ten-minute operation. The agent framework abstracts the model layer precisely so you don’t have to commit to a single provider.
Your deployment infrastructure? That’s not a ten-minute swap. That’s a weekend migration at best, and a full re-architecture at worst.
When you choose to self-host OpenClaw on bare metal versus a managed container service versus a dedicated hosting platform, you’re making decisions about security posture, uptime guarantees, credential management, monitoring capabilities, and scaling behavior that will define your agent’s operational reality for months or years.
And yet, most teams spend three weeks evaluating LLMs and thirty minutes setting up their deployment.
That ratio is backwards.
What Deployment Actually Controls
To understand why infrastructure trumps model selection, you need to understand what an OpenClaw agent actually does at runtime. A detailed breakdown of OpenClaw’s internal agent loop and architecture reveals a system that’s fundamentally different from a typical API-backed application.
An OpenClaw agent runs a continuous perceive-think-act-reflect cycle. It maintains persistent connections to multiple chat platforms. It writes to and reads from a memory layer. It executes tools – browsing the web, running code, managing files, calling external APIs. And it does all of this concurrently, often across multiple conversations simultaneously.
This is not a stateless request-response service. It’s a long-running, stateful process with persistent connections, mutable state, and real-world side effects.
That architectural reality means your deployment infrastructure determines:
Uptime and reliability. A model API going down for 30 seconds means a slightly delayed response. Your hosting infrastructure going down means your agent vanishes – mid-conversation, mid-task, mid-action. For agents managing customer interactions or business workflows, that’s not a minor inconvenience.
Security boundaries. The model processes text. Your infrastructure determines whether that processing happens in a sandboxed container or on a shared VPS with your production database. CVE-2026-25253 – the one-click RCE vulnerability that hit OpenClaw in January – was a model-agnostic infrastructure exploit. It didn’t matter which LLM you used. It mattered whether your deployment was isolated.
Credential safety. Your agent holds API keys for every service it connects to. Your deployment infrastructure determines whether those credentials are encrypted at rest with AES-256 or sitting in plaintext in a .env file on a server that 30,000 other OpenClaw operators also left unprotected.
Behavioral monitoring. When Meta researcher Summer Yue’s OpenClaw agent deleted her emails and ignored stop commands, the failure wasn’t the model’s reasoning – it was the absence of an infrastructure-level circuit breaker that could have detected anomalous behavior and killed the process.
See also: Fashion Product Developer and Tech Designers
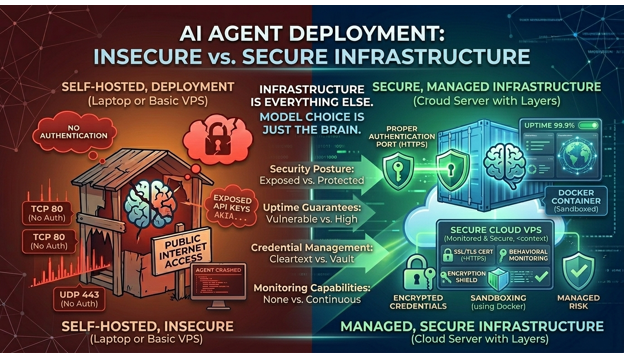
The Self-Hosted Trap: Maximum Control, Maximum Burden
The DevOps instinct is to self-host everything. I get it. I share it. Control over your infrastructure is a legitimate engineering value.
But self-hosting OpenClaw is a genuinely different beast than self-hosting a web application.
A web app is stateless (mostly). You deploy it, put a load balancer in front, and horizontal scaling is straightforward. OpenClaw agents are stateful, long-running processes with persistent connections and mutable memory. The operational model is closer to running a database than running a web server.
Here’s what a production-grade self-hosted OpenClaw setup actually requires: Docker with resource-constrained containers, a reverse proxy with TLS termination, persistent storage for agent memory, a process manager for automatic restarts, log aggregation for behavioral audit trails, a monitoring stack with alerting, credential encryption (not just environment variables), and a patching cadence that keeps up with OpenClaw’s rapid release cycle.
That’s not a weekend project. That’s an ongoing operational commitment of 4-8 hours per month for maintenance alone – patching, updating, debugging, rotating credentials.
For a dedicated DevOps team with spare capacity, this is manageable. For a startup engineering team trying to ship product, it’s an expensive diversion.
Stay with me here.
The Managed Middle Ground
The alternative to self-hosting isn’t giving up control. It’s choosing which controls matter and outsourcing the ones that don’t differentiate your product.
Today, the managed OpenClaw infrastructure space has several options at different abstraction levels. DigitalOcean’s 1-Click Droplet simplifies server provisioning but still requires you to manage Docker, security, and updates. xCloud and Elestio offer semi-managed hosting with more infrastructure handled for you. A full comparison of self-hosted versus managed OpenClaw deployment trade-offs at BetterClaw maps exactly what you retain control over and what gets abstracted at each level – from container orchestration to credential encryption to anomaly monitoring.
The right choice depends on your team’s operational capacity and what you consider core versus commodity.
If your competitive advantage involves custom agent infrastructure – you’re building a product on top of OpenClaw – then self-hosting makes sense. You need that control.
If you’re using OpenClaw agents as internal tools or customer-facing automation, the deployment infrastructure is commodity. It needs to work. It needs to be secure. It doesn’t need to be your engineering team’s side project.
The Monitoring Gap Nobody Talks About
This is where it gets interesting.
Most OpenClaw deployments – self-hosted or managed – have zero behavioral monitoring. They track whether the process is running (basic uptime) but not what the process is doing.
That’s like monitoring whether your database server is online but never looking at query logs.
For autonomous agents, behavioral monitoring isn’t optional. It’s the only way to catch:
- Agents taking actions outside their intended scope
- Gradual drift in agent behavior as memory accumulates
- Anomalous interaction patterns that suggest exploitation
- Resource consumption spikes that indicate runaway loops
The ClawHavoc campaign – 824 malicious skills affecting ~20% of the ClawHub registry – succeeded partly because compromised agents looked normal from an infrastructure perspective. They were up. They were responsive. They were also quietly exfiltrating data through legitimate-looking API calls.
Infrastructure-level behavioral monitoring – logging every action, analyzing patterns, auto-pausing on anomalies – is the security layer that separates production-grade deployments from ticking time bombs. Managed platforms like Better Claw and some hardened self-hosted configurations include this by default. Most ad-hoc deployments don’t.
If you’re running OpenClaw in production today without behavioral monitoring, fixing that should be a higher priority than your next model evaluation.
Where This Is Heading
Peter Steinberger joining OpenAI and OpenClaw moving to an open-source foundation will likely accelerate standardization around deployment best practices. The 44,000+ forks suggest the community has appetite for it.
But right now, the infrastructure layer is the wild west. And that’s where the real engineering decisions live.
The next time you find yourself in a 45-minute debate about GPT-4o versus Claude Sonnet versus Gemini Pro, ask yourself: how much time did we spend on our deployment architecture? On credential management? On monitoring? On our security posture?
If the answer is “less time than we spent on model benchmarks,” your priorities might be inverted.
The model is the brain. The infrastructure is everything else – the nervous system, the immune system, the skeleton. You can swap brains. You can’t easily swap the body it runs in.
Build the body right first. The brain is the easy part.


